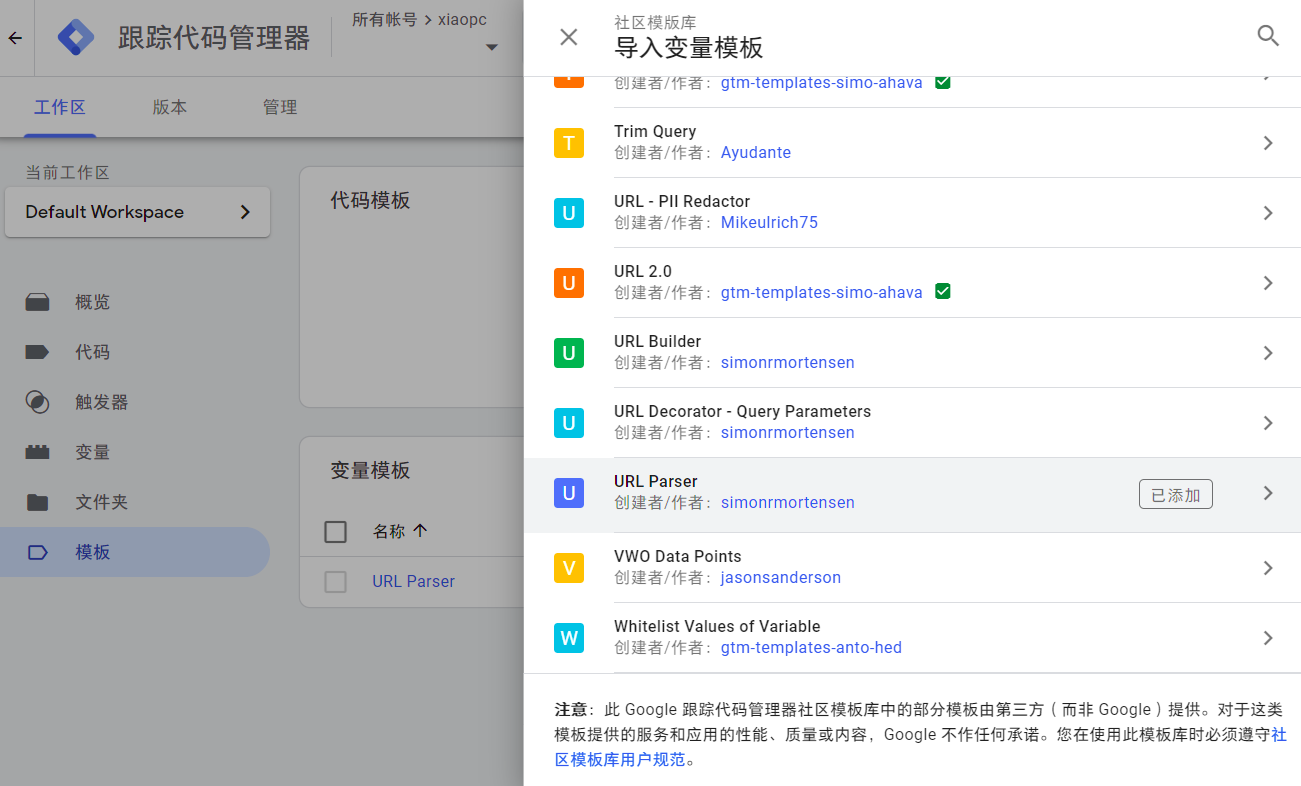
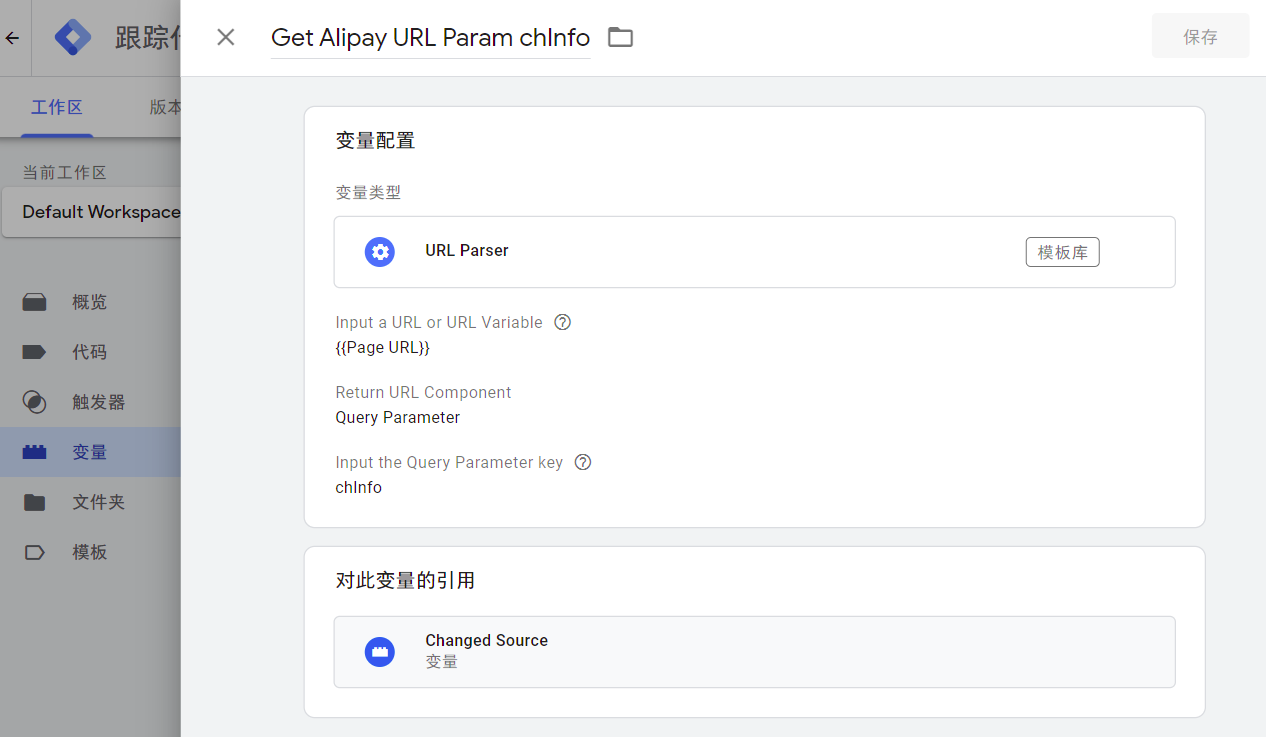
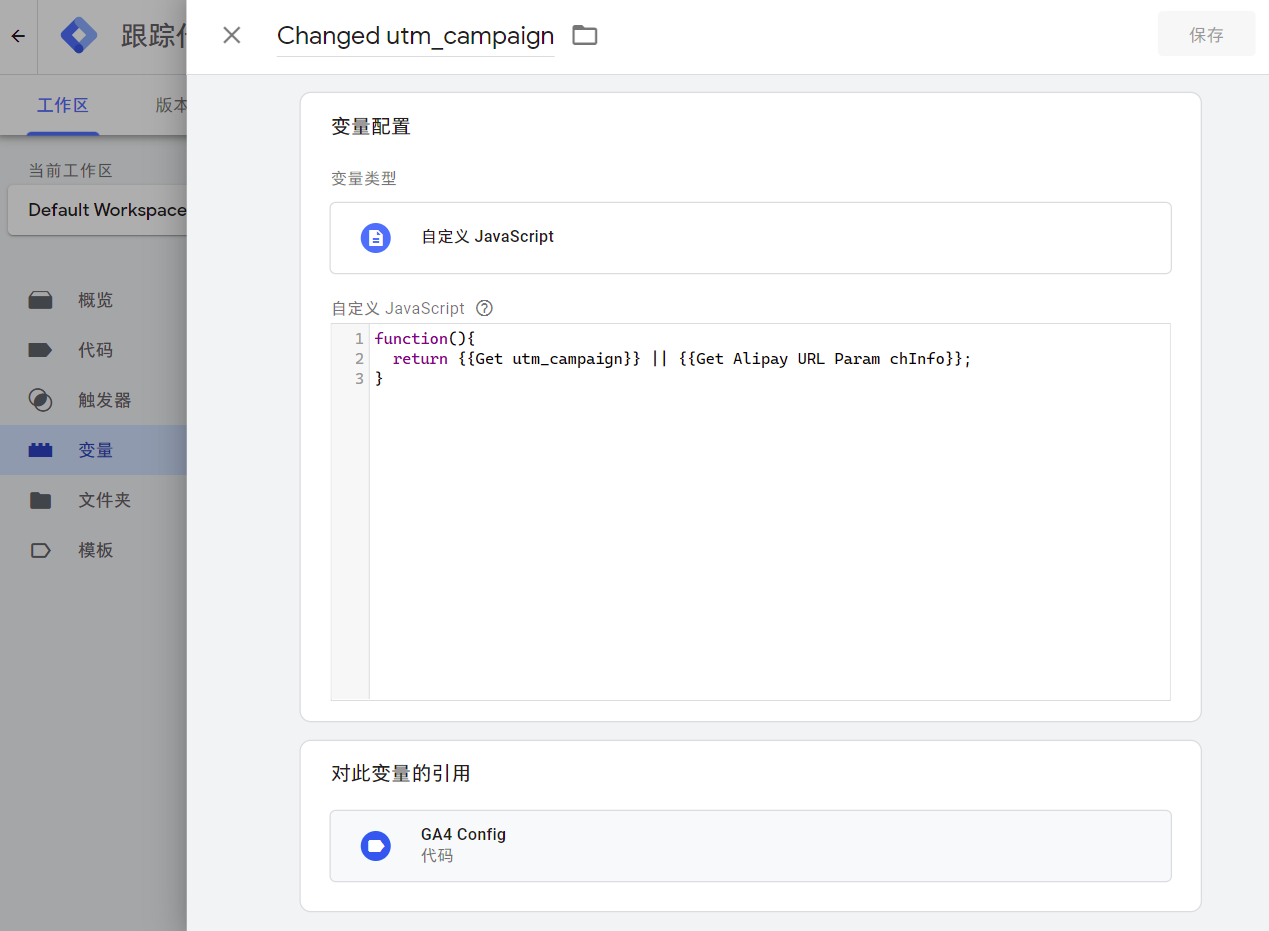
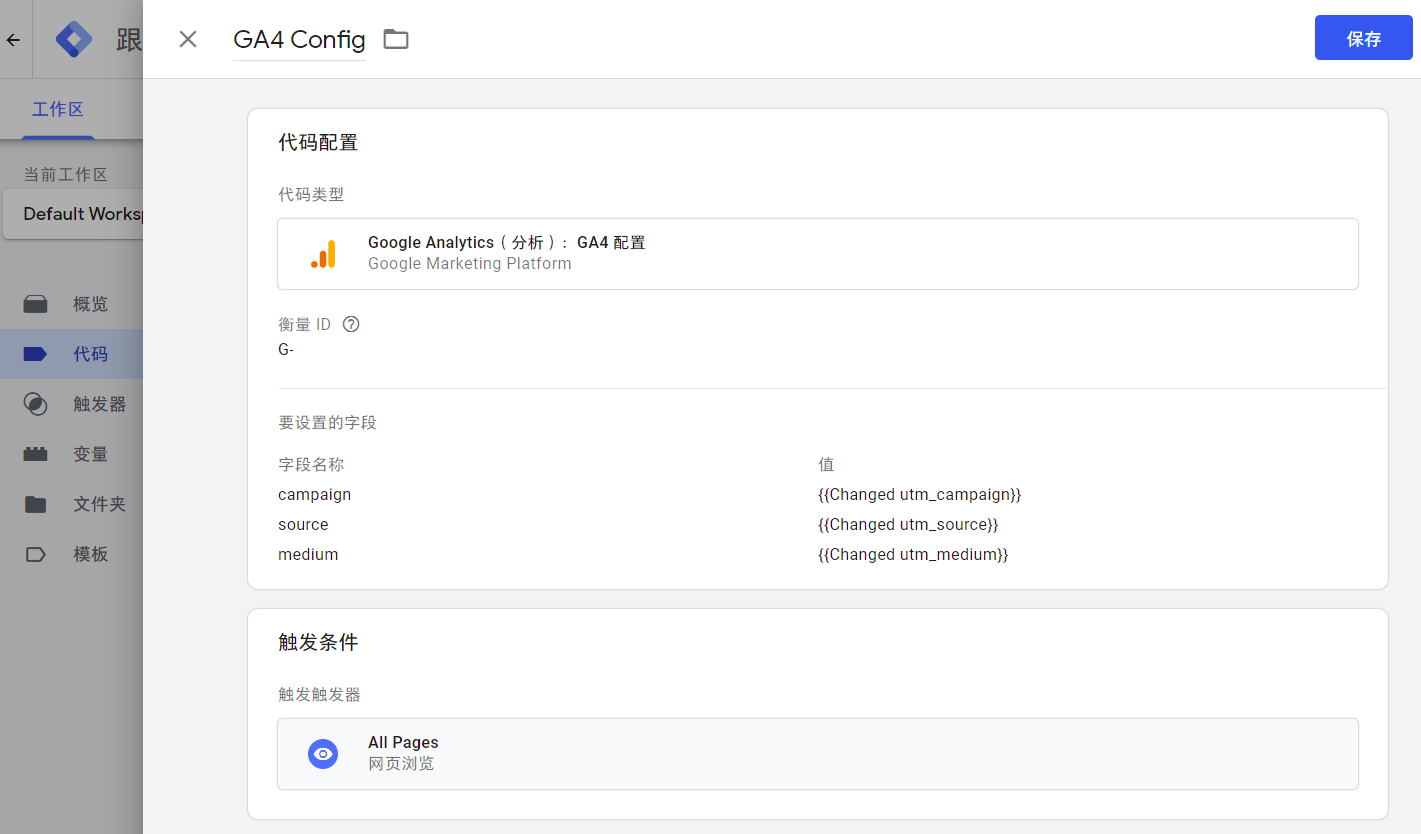
0. 数据长什么样
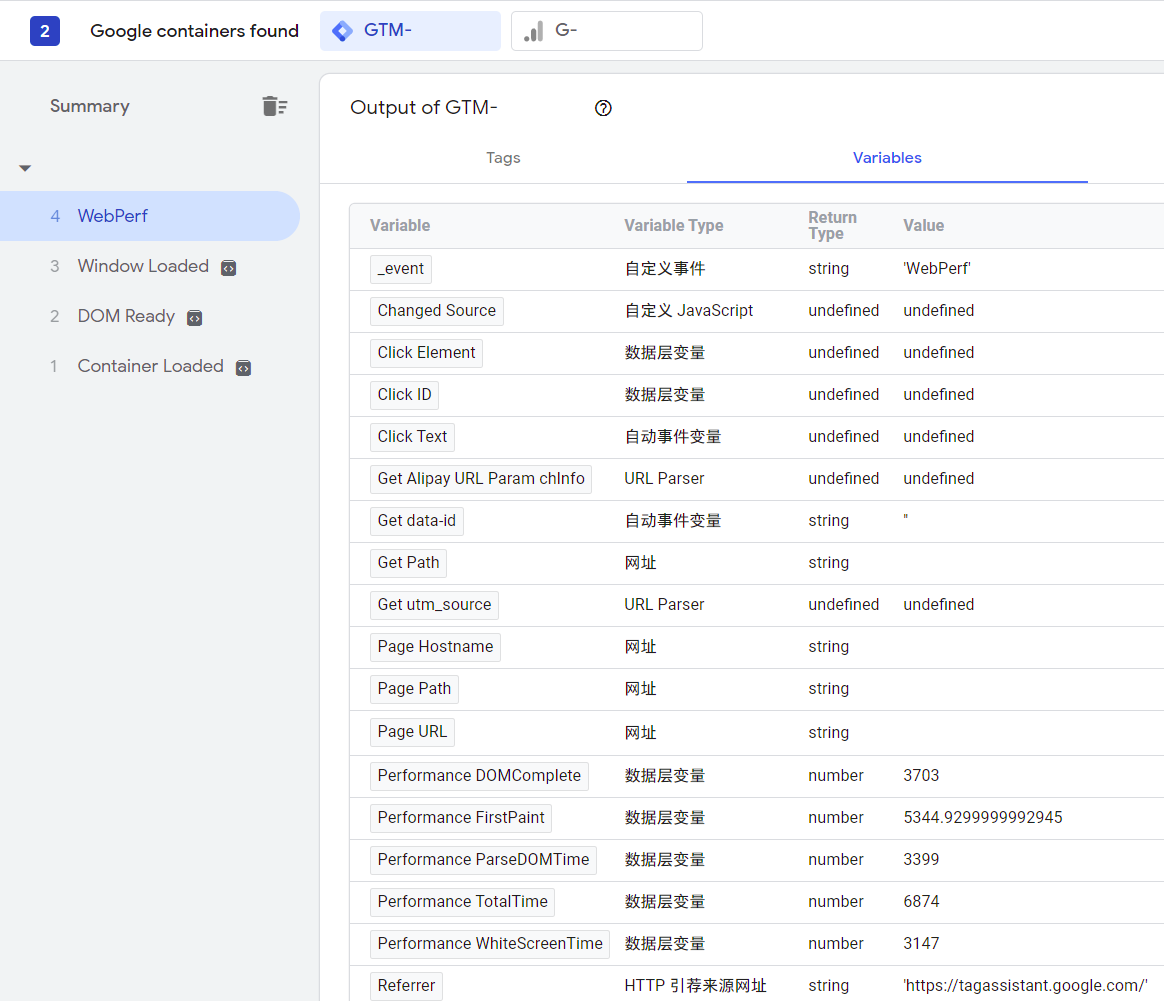
前文说到,GA4 的全部回报均为事件驱动,那么数据就是一系列事件组成的集合,每个事件有一定的属性...
这不就是结构化数据嘛,结构化数据查询语言是... SQL 啊...
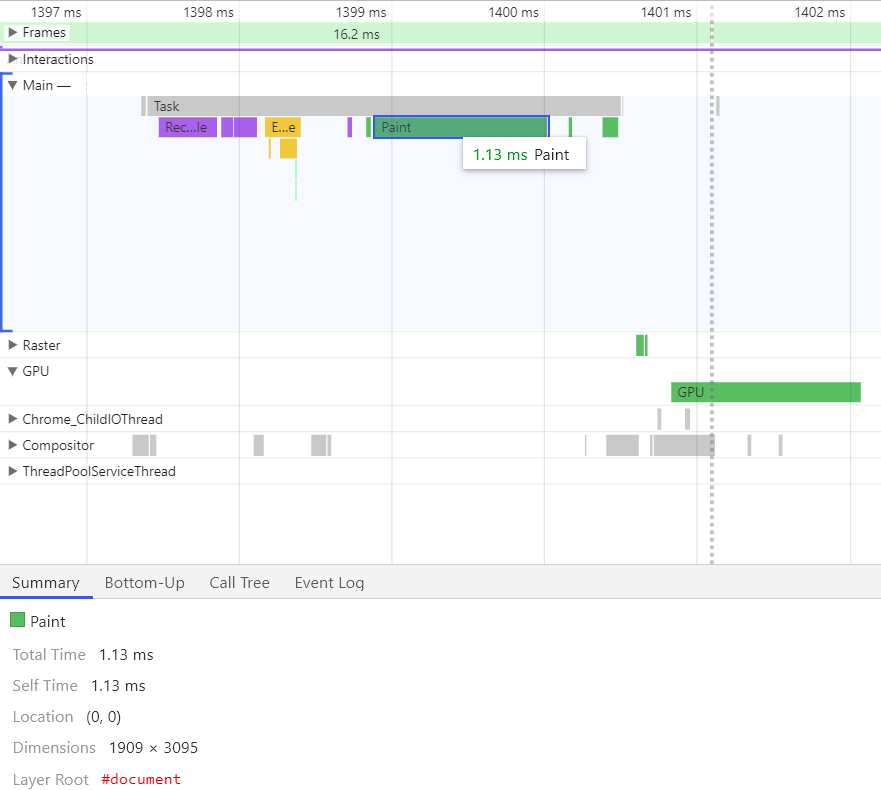
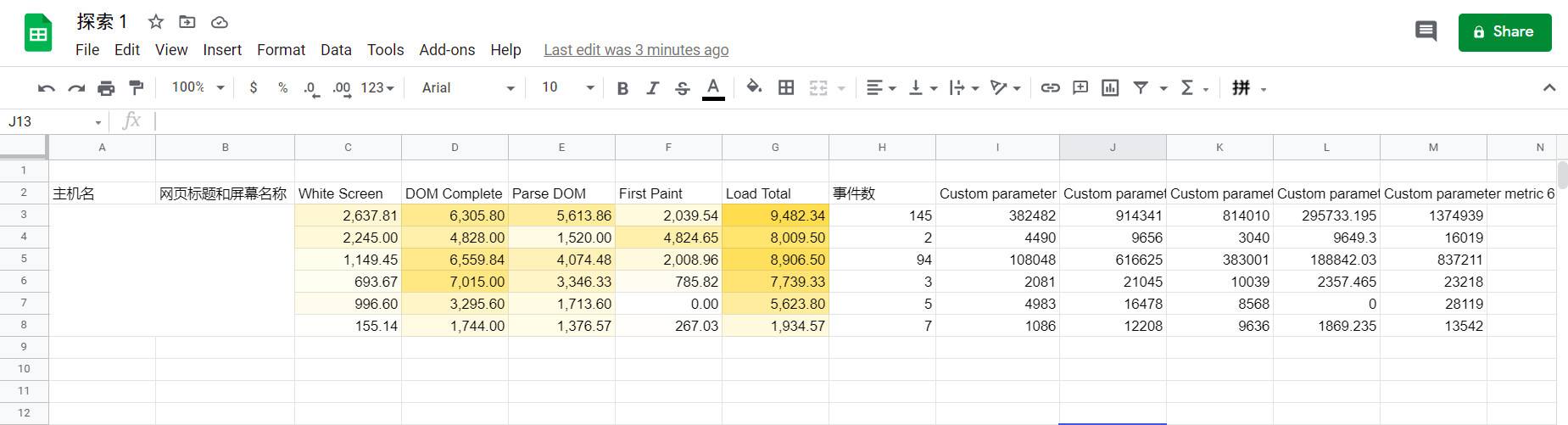
GA4 给到的原始数据表就是这样的:
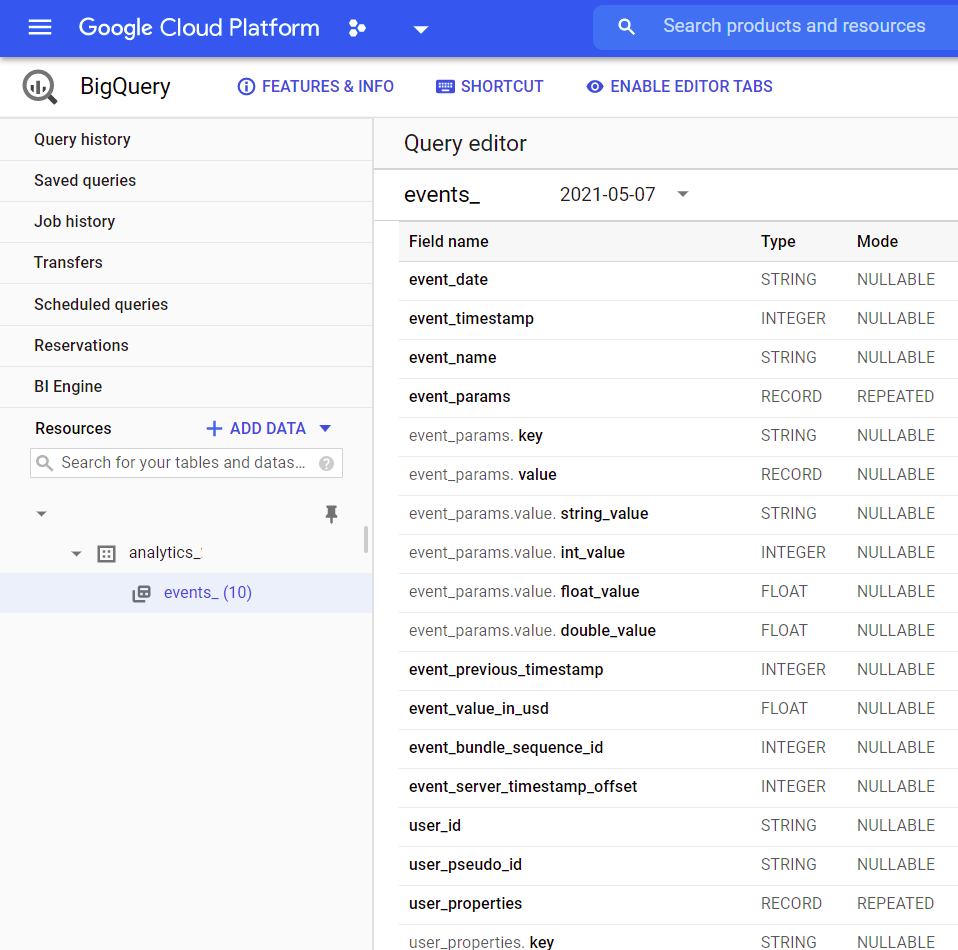
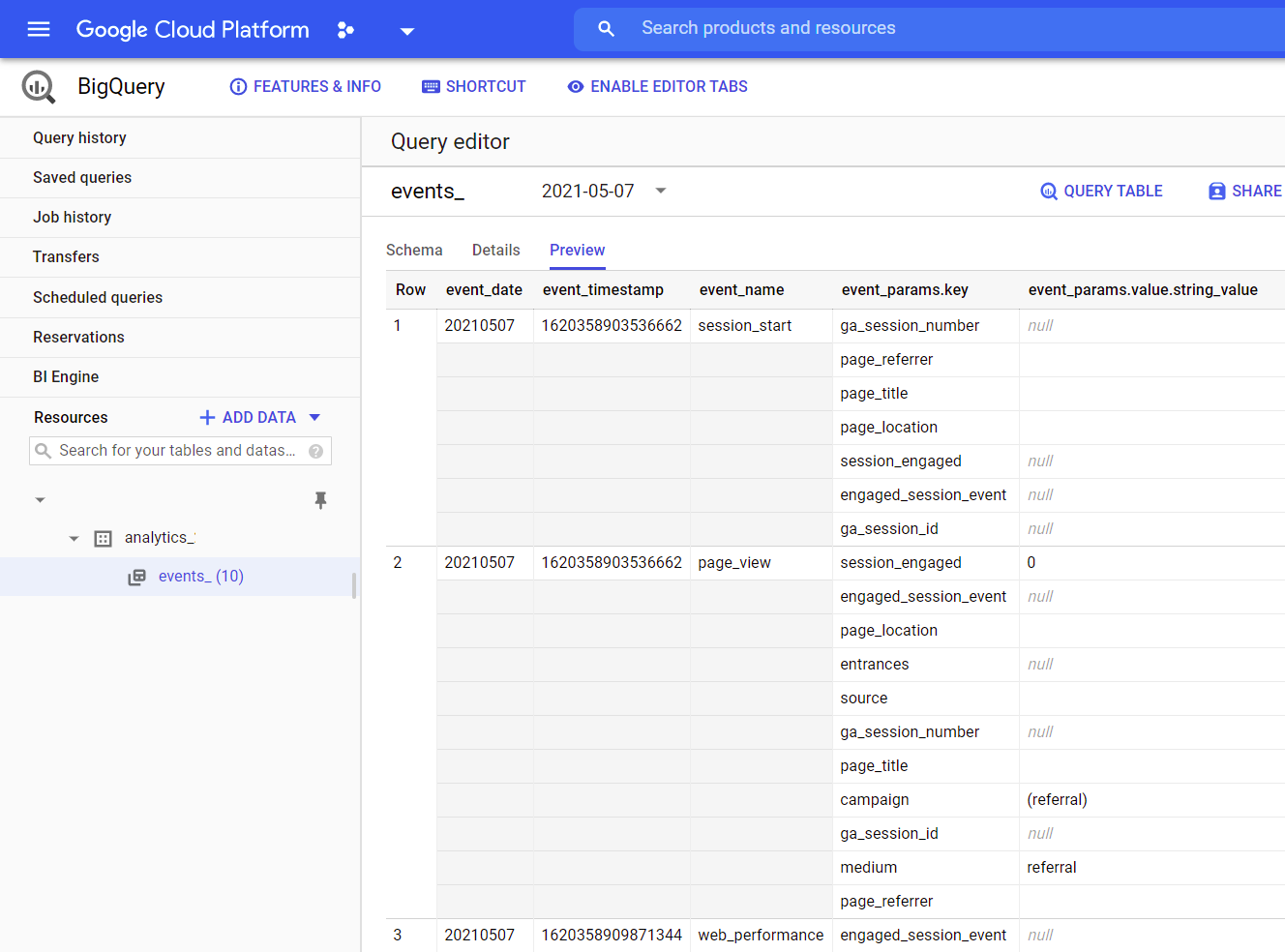
不过看起来和传统关系型数据库有一点点不一样,这个下面再说.
1. 开始设置转发
打开 GA4 的管理 - BigQuery 关联,点击「关联」.
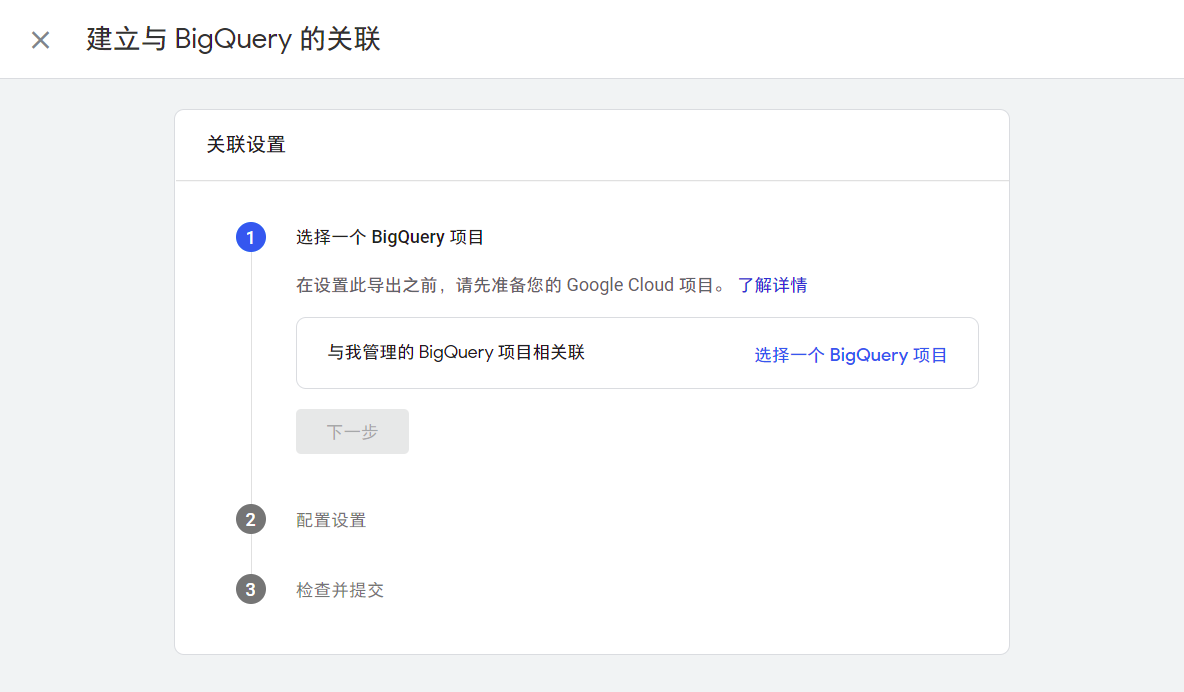
点击「选择一个 BigQuery 项目」,勾选一个 BigQuery 项目.
没有 BigQuery 项目,或是勾选后提示「所选的 Google Cloud 项目未启用 BigQuery API」怎么办呢?
那你一定没开通 Google Cloud 吧.
但不想开通(不想浪费掉新用户免费试用)怎么办呢?开一个 Firebase 就有了。
(不需要的可以跳过下一节)
2. 白嫖 Firebase
Firebase 是 Google 的开发者平台,由于「混乱的大公司」问题,它并没有被合并到云服务部门,而且它还送独立的云服务资源.
打开 Firebase,创建一个免费的项目(这里就不截图了).
侧边栏齿轮 - Project Settings - Integrations - BigQuery:
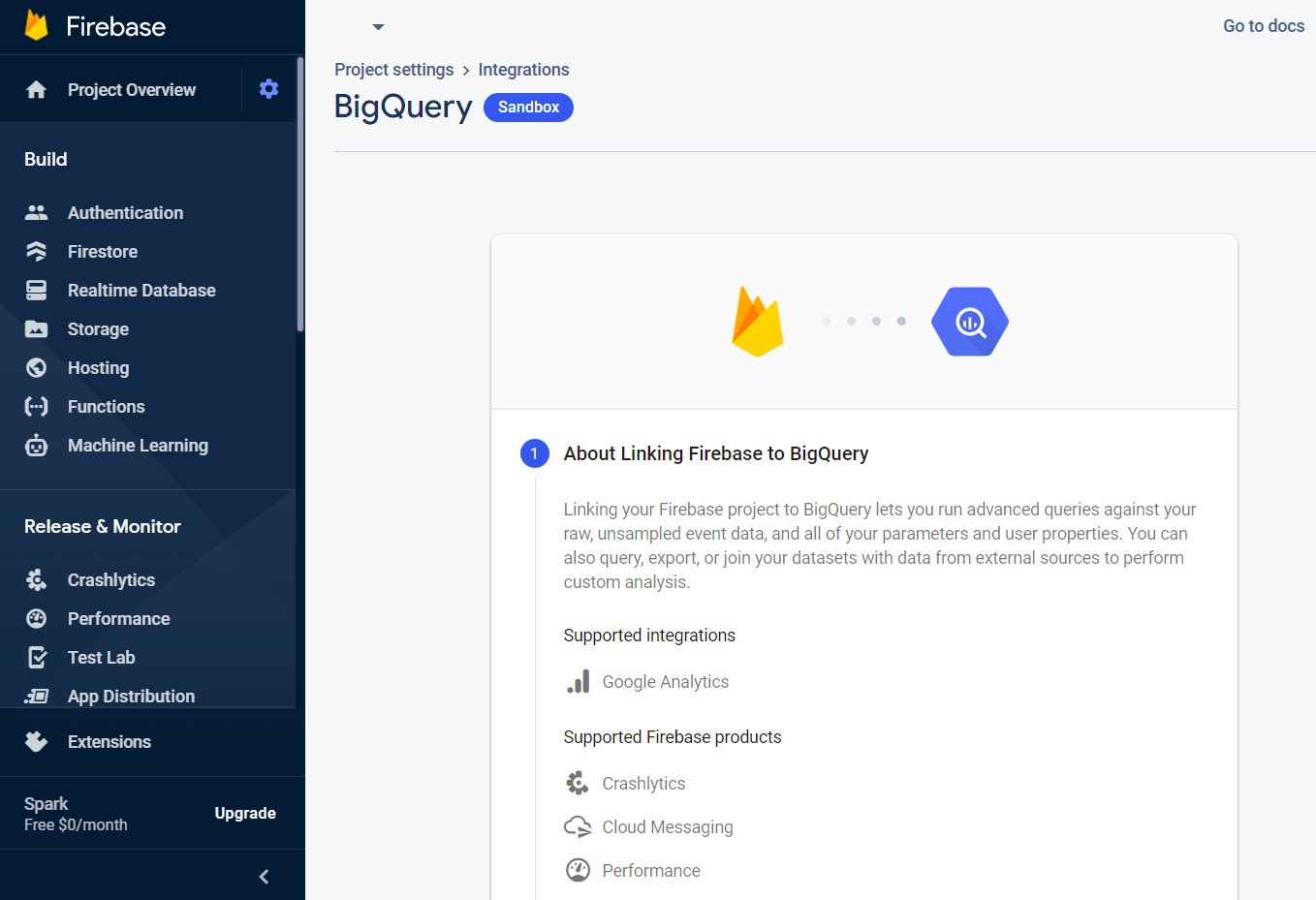
这里写到,免费版提供的 BigQuery 是沙箱,只保留 60 天数据,最大 10GB.
然后点 Continue 继续,在第二步所有的选项都不勾选(可以看到,基本上提供的都是 App 开发服务),然后点 Link to BigQuery.
显示可用空间 10GB 就表示已经完成了.
3. 完成配置转发
回到刚才的 GA4 关联向导,这时就可以选刚才创建的 Firebase 项目提供的那个.
数据位置随便选,多个项目关联到同一个 BigQuery 的话,位置必须选一样的. 然后下一步.
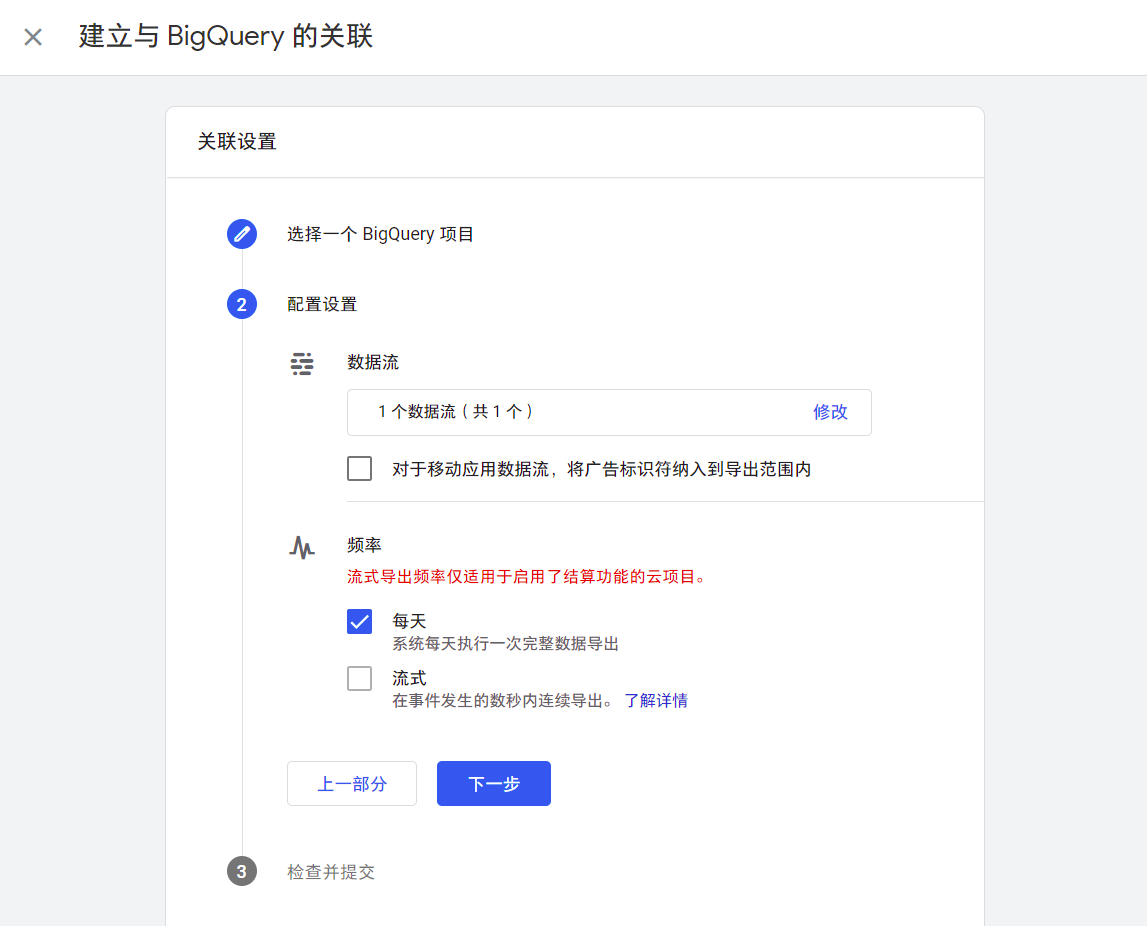
勾选「每天」,当然付费用户可以选择流式.
每天的导出时间大概在 GMT 零点后,也就是北京时间早上八点.
点下一步,提交,配置转发就完成了,接下来就是等第二天看数据.
4. BigQuery 初上手
那么哪里才能找到 BigQuery 呢?当然是 Google Cloud 了.
Google Cloud 用户可以在导航栏的 Big Data 类目找到,也可以通过 https://console.cloud.google.com/bigquery 直接进入.
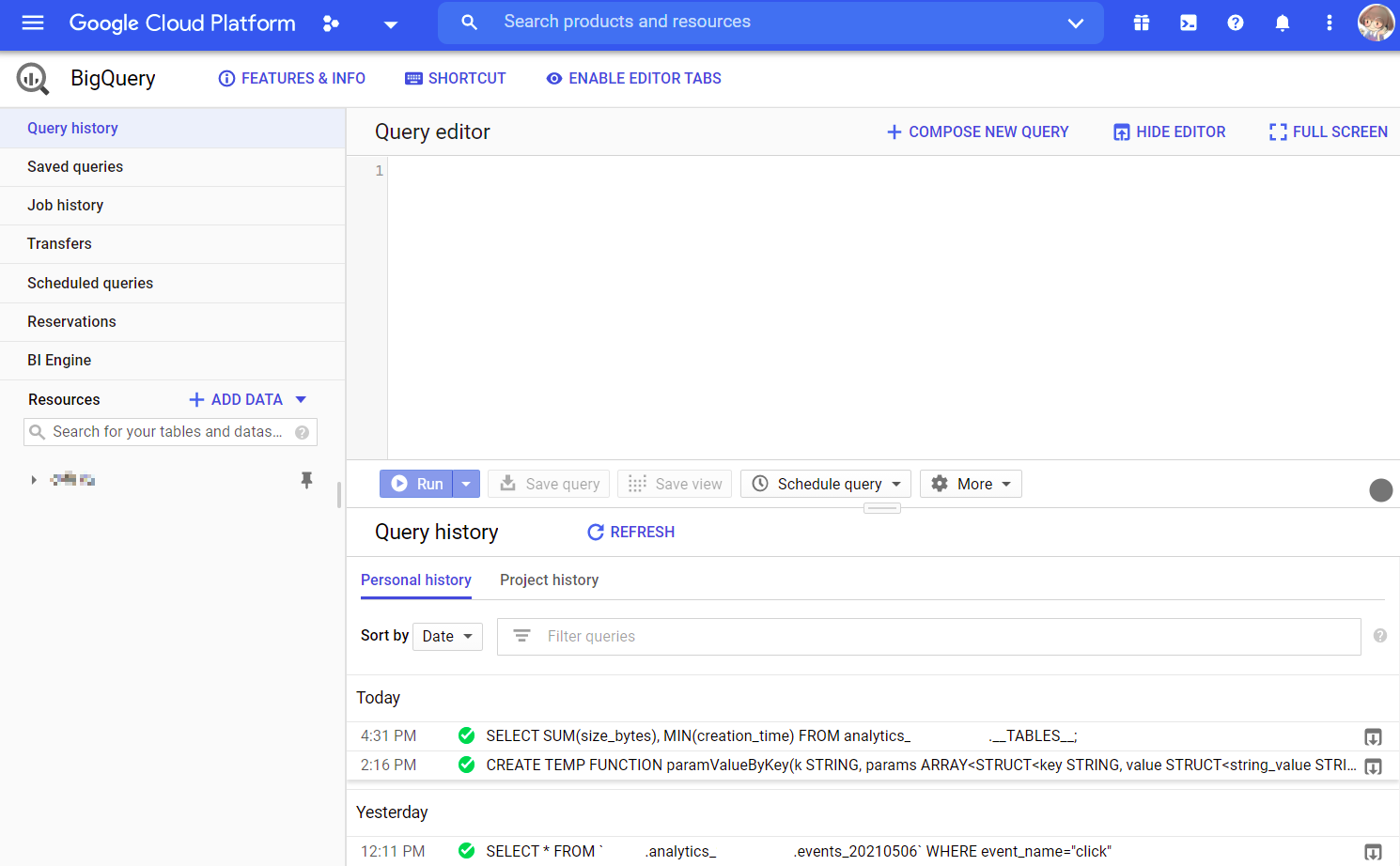
左边栏是功能及数据集树状图,右边分别是查询语句输入和查询结果窗格,和传统数据库客户端基本一样.
它的 SQL 也是标准的 SQL 语言,符合 SQL 2011 标准,有问题可以查官方文档.
(之前 BigQuery 用的不是标准 SQL,遗留问题不必管他)
数据的层次是项目-数据集-表,也很像. 数据集默认命名是 analytics_统计ID,表就是 events_.
(这里是把每日的 events_日期 表合并显示了)
选中 events_ 表,点 Query Table 会自动写当前表的 SELECT FROM 语句.
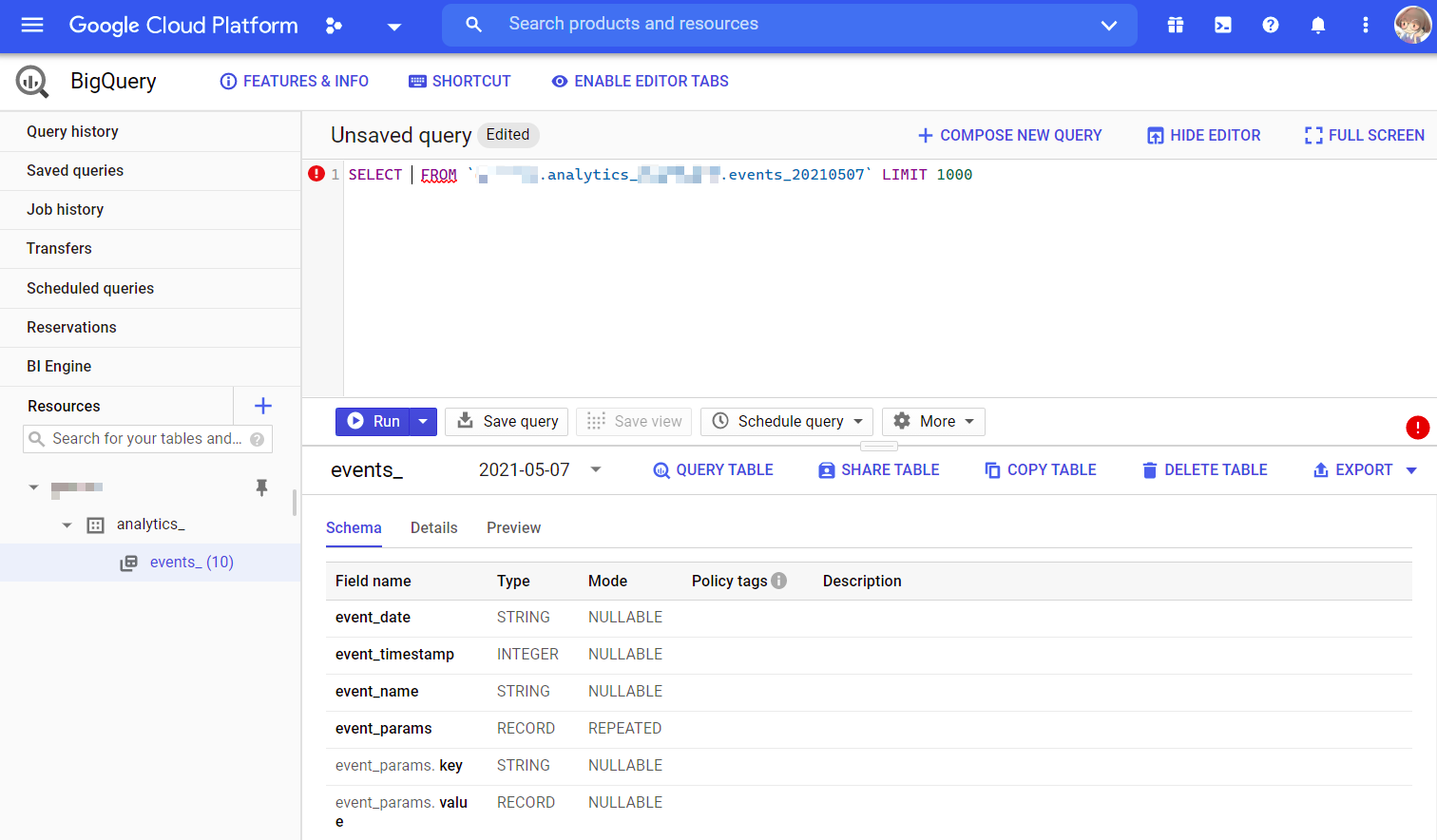
可以看到,有语法检查. 这个语法检查有两个层级,一是语法检查,二是结合数据表检查.
(对真大数据玩家来说,可以节约一点时间)
4. 实测:统计跳出
统计跳出站外的链接这个需求,很少有统计系统去做.
GA4 里明明能看到 click 事件,还能在实时监控里看到最近的 link_url 事件属性,然而在统计里就是调不出来.
所有指标里就是没有这个属性,把这个属性设置自定义指标也拿不到数据,这就令人难受了.
(如果有调出来的方法的话可以留言)
那就只能用 BigQuery 看看.
但是,如果写一个这样的 SQL 查询:
1 | SELECT event_params |
会得到 event_params.key, event_params.value.string_value, event_params.value.int_value, event_params.value.float_value, event_params.value.double_value 这些项.
然而用点号访问,例如 event_params.value.string_value,会得到一个错误:
Cannot access field value on a value with type ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, ...>>>
event_params 被定义为嵌套了数组(ARRAY)和结构体(STRUCT)的数据,ARRAY 包括每个属性,每个属性有属性名和属性值,属性值还分 string/int/float...
啊,这就难到学老版本 SQL 标准的了. 不过感谢万能的 StackOverflow,文末的参考链接给出了一个辅助函数:
1 | CREATE TEMP FUNCTION paramValueByKey(k STRING, params ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64 >>>) AS ( |
定义了一个临时函数(每次请求都要定义)paramValueByKey('属性名', event_params),取出这个属性.
那么,统计 click 事件的 link_url 的次数就可以这么写:
1 | SELECT url, COUNT(*) AS count |
前面跟上辅助函数的实现,提交,就有了.
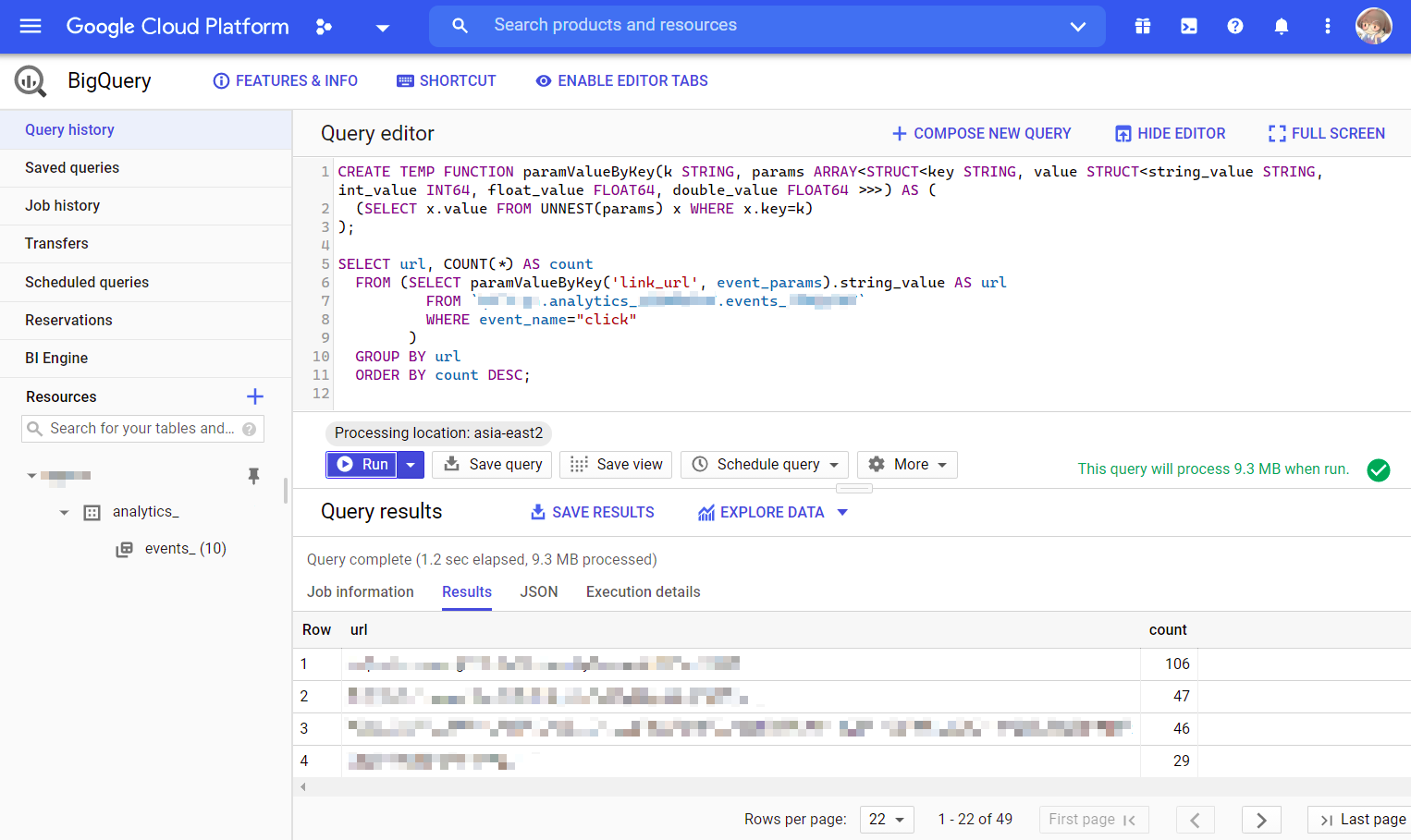
点击 Save Results 可以把结果导出到本地或者 Google Drive.
本文参考了:
https://stackoverflow.com/questions/41090396/how-to-select-multiple-custom-firebase-event-parameters-in-bigquery
]]>